class: center, middle # Information Extraction In Illicit Web Domains ### WWW 2017 --- # Outline ####1. Introduction ####2. Related Work ####3. Approach ####4. Evaluations ####5. Conclusion ### Keywords Information Extraction;Named Entity Recognition;Illicit Domains;Featrue-agnostic;Distributional Semantics; --- # Introduction #### How to build knowledge graphs? 1. *domain discovery* > spider & domain ontology 2. *information extraction system* > CRFs & DNN -> extraction of name entities and relationship <br /> <br /> <br /> <br /> <br /> While IE has been well-studied both for cross-domain Web sources (e.g. Wikipedia) and for traditional domains, it is less well-studied for dynamic domains that undergo frequent changes in content and structure. --- #### Challenges to illicit domain IE system: 1. deliberate information obfuscation 2. non-random misspelling of common words 3. high occurrences of OOV and uncommon words 4. frequent use of Unicode characters 5. sparse content 6. heterogeneous website structure 7. ... #### Examples Hey gentleman im neWY0rk and i’m looking for generous... > New York AVAILABLE NOW! ?? - (4 two 4) six 5 two - 0 9 three 1 - 21 > (424)652-0931-21 --- #### High level overview .img[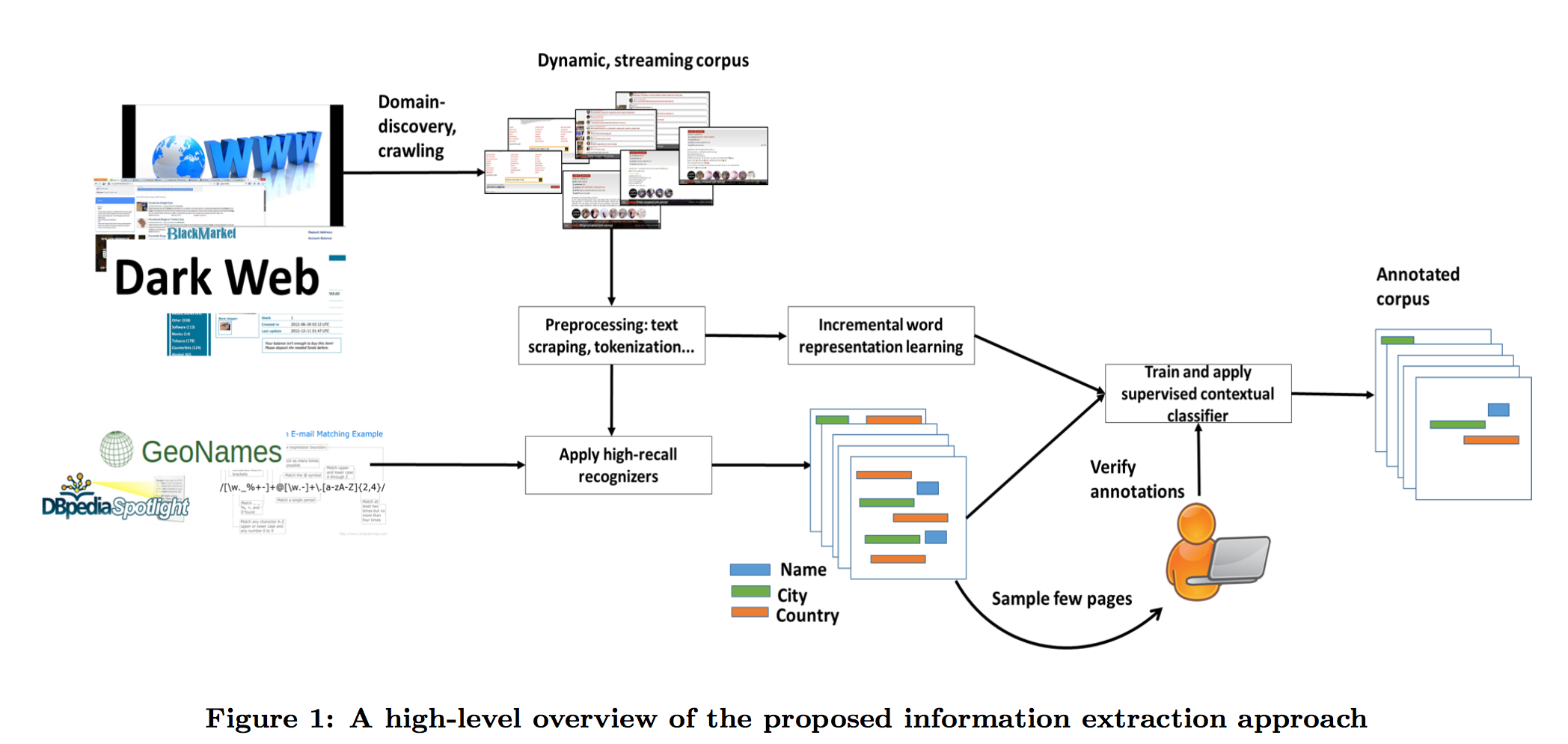] .center[High-recall recognizer + Supervised feature-agnostic classification algorithm] --- #### Contribution Present a lightweight feature-agnostic information extraction system for a highly heterogeneous, illicit domain like human trafficking #### Baseline latest Stanford Named Entity Resolution system (CRF) # Related Work **Open IE** *The specific problem of devising feature-agnostic, low-supervision IE approaches for illicit Web domains has not been studied in prior work* --- #Approach ####1. Pre-processing ####2. Deriving Word Representations ####3. Applying High-Recall Recognizers ####4. Supervised Contextual Classifier --- ## Pre-processing #### 1. Scrape website #### 2. Extract text > RTE(Readability Text Extractor) > Tune RTE to achieve high recall > https://www.readability.com/developers/api #### 3. Tokenizer > NLTK --- ## Deriving Word Representations **Random Indexing** > Naive version of thie Random Indexing algorithm > Improve: define some **compound unit** ----- | Unit name | Definition | | --- | --- | | High-idf-units | Units occurring in fewer than fraction theta (by default, 1%) of initial corpus | | Pure-num-units | Numerical units | | Alpha-num-units | Alpha-numeric units that contain at least one alphabet and one number | | Pure-punct-units | Units with only punctuation symbols | | Alpha-punct-units | Units that contain at least one alphabet and one punctuation character | | Nonascii-unicode-units | Units that only contain non-ASCII characters | ----- RI algorithm **only** learn a single vector for each compound unit. --- ## Applying High-Recall Recognizers ## Supervised Contextual Classifier .img[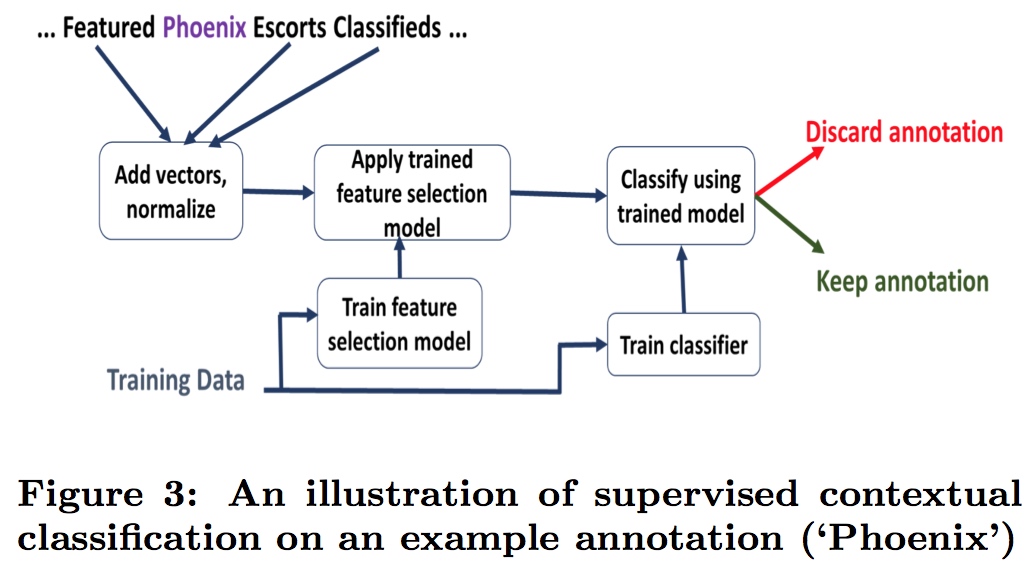] --- # Evaluations ### Dataset DARPA MEMEX program. ### Ground-truths Apply four high-recall recognizer for a website in a part of dataset, and manually verifying. ### Attribute 1. City (in HTML title) 2. City (in scraped text) 2. State 3. Name 4. Age --- .img[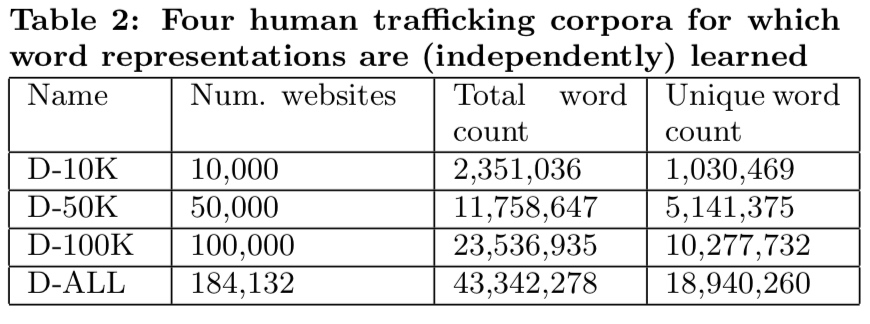] .img[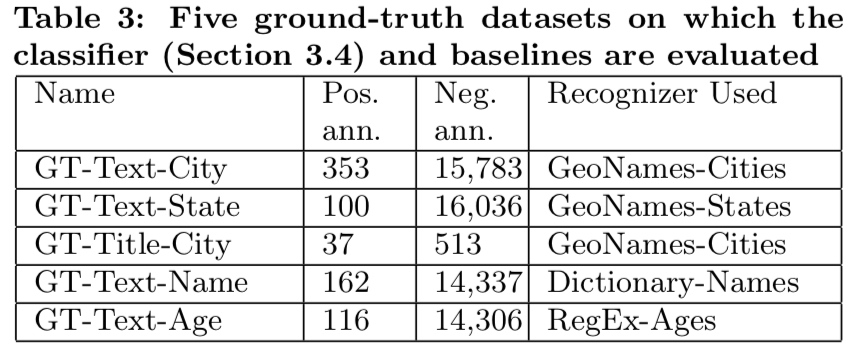] --- ### System Author developed 4 high-recall recognizers: 1. GeoNames-Cities 2. GeoNames-States 3. RegEx-Ages 4. Dictionary-Names > Cities and states dataset relies on http://www.geonames.org/ (A freely avaliable geoname dataset) > Ages recognizer can only recognise age between 18 and 31. > Name dictionaries are collected from freely dataset in muiltiple contries and languages. --- ### Baseline *Stanford Named Entity Recognition system(NER)* > Re-trained at randomly samplying 30% of ground-truth dataset, remaining annotations used for testing. > Re-trained at randomly samplying 70% of ground-truth dataset, remaining annotations used for testing. .img[] --- ### Parameters ####Random Indexing algorithm *Dimension - 200* *Sparsity ratio - 0.01* *Context window - (2,2)* ####Classifier *Random forest* *10 trees* *Gini impurity* *Use k-best feature - k=20* --- ### Result .img[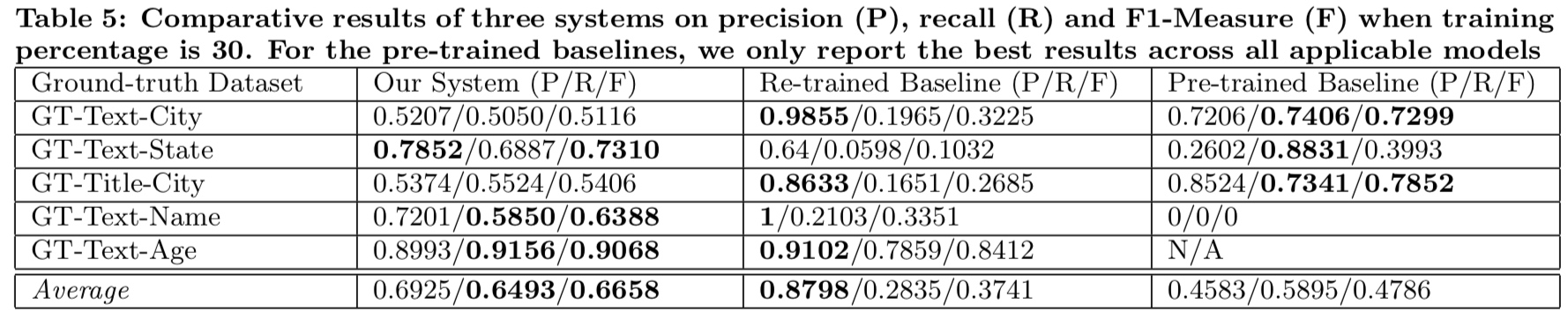] .img[] --- class: center .img-70[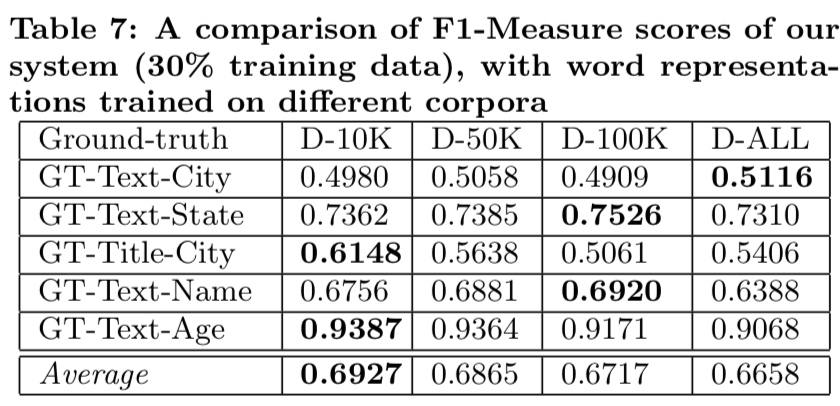] .img-70[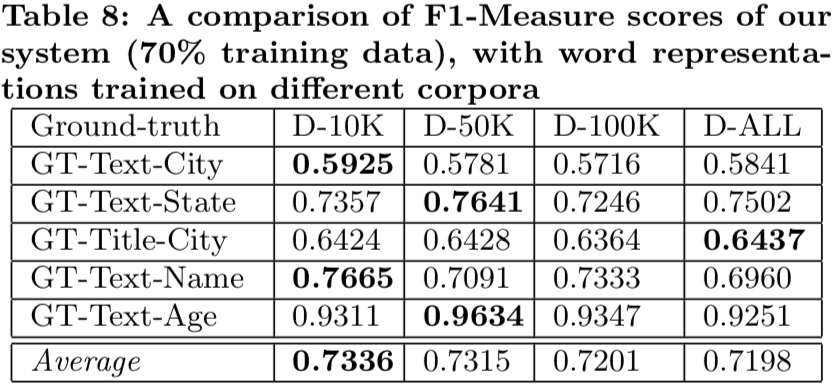] --- class: center .img-70[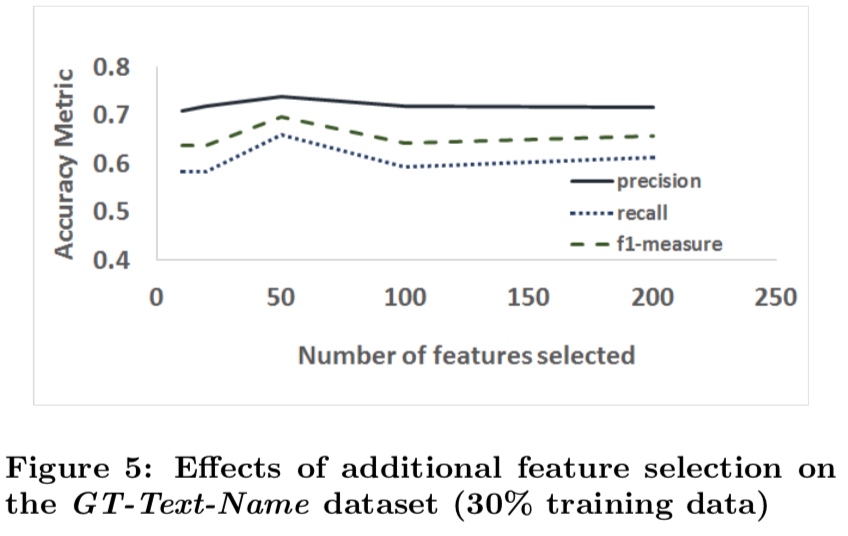] .img-70[] --- class: center .img-70[] .img-70[]